Búsqueda de los exones con el mayor número de SNPs
Unión (‘joining’) de exones y SNPs
Recordemos que nuestro objetivo es encontrar los exones con un mayor número de SNPs. El primer paso para ello es obtener la unión (joining) de exones y SNPs (obteniendo así un listado de los exones y SNPs que solapan).
En el menú de la izquierda -> “Operate on Genomics Intervals -> Join“:
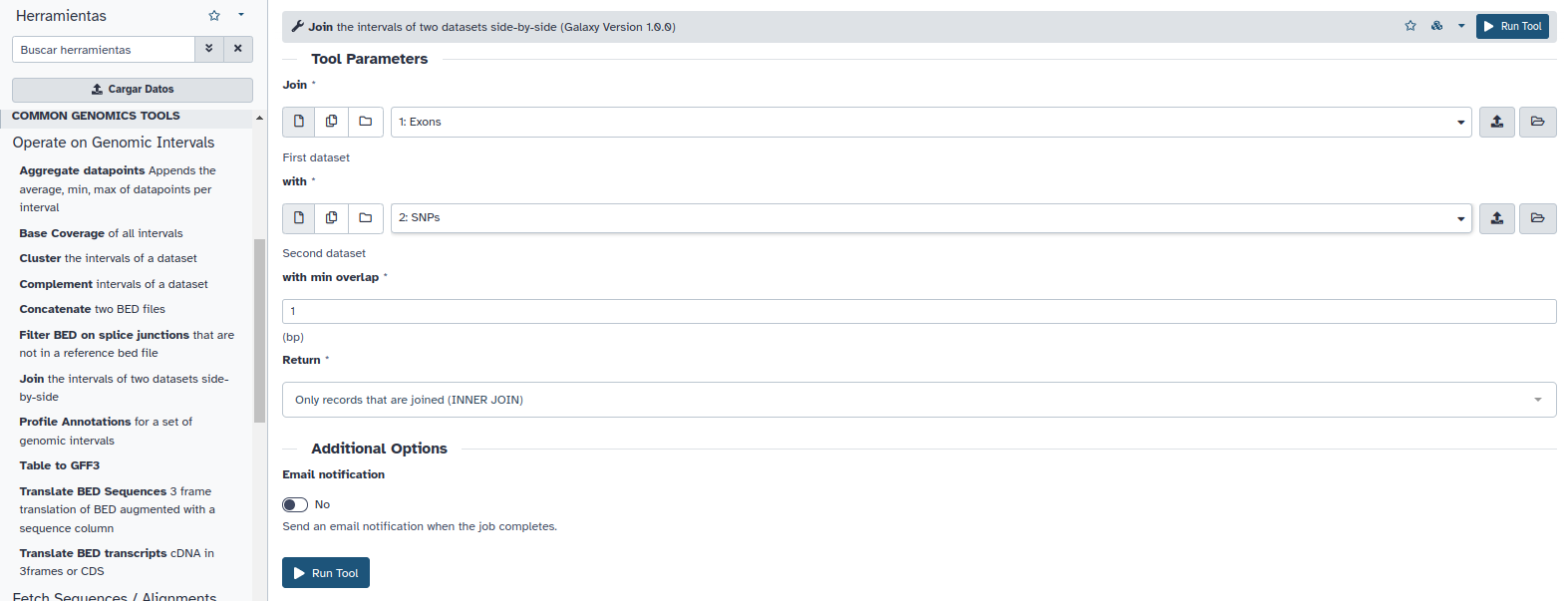
Es importante seleccionar primero el contendor (los exones) y luego el continente (los SNPs). Nótese que existen muchas maneras de obtener la intersección entre dos conjuntos de datos tanto a nivel de solapamiento entre elementos (por defecto 1bp) como del tipo de resultados que queremos obtener (por defecto INNER JOIN, devuelve todos los contenedores con algún continente).

Deje las opciones por defecto y pinche en Execute. Obtendrá un tercer item en su historia:
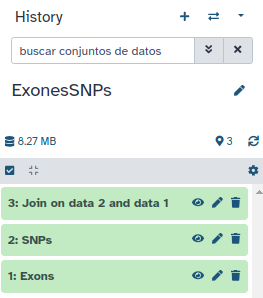
Pinchando en el botón ‘Ojo’ puede examinar los datos que contiene este nuevo item de su historia:

Observe detenidamente estos datos (tenga en cuenta que pueden variar ligeramente si está haciendo este ejercicio con una versión más reciente de la base de datos).
Las primeras seis columnas corresponden a los exones y las cuatro últimas a los SNPs.
Puede ver, por ejemplo, que el exon con ID NM_001005239.2_cds_0_0_chr22_15528192_f contiene 2 SNPs con IDs rs78350717 y rs9617249. Mientras que el segundo exón que aparece (NM_001136213.1_cds_0_0_chr22_15690078_f) contiene 4 SNPs con IDs rs200013384, rs201322170, rs199952431 y rs200013113.
Número de SNPs por exon
Hemos visto que el exon NM_001136213.1_cds_0_0_chr22_15690078_f se repite cuatro veces, una línea por elemento continente (SNPs). Por tanto, podemos calcular el número de SNPs por exon contando simplemente el numero de repeticiones del nombre de cada exon. “Join, Subtract, and Group -> Group“:
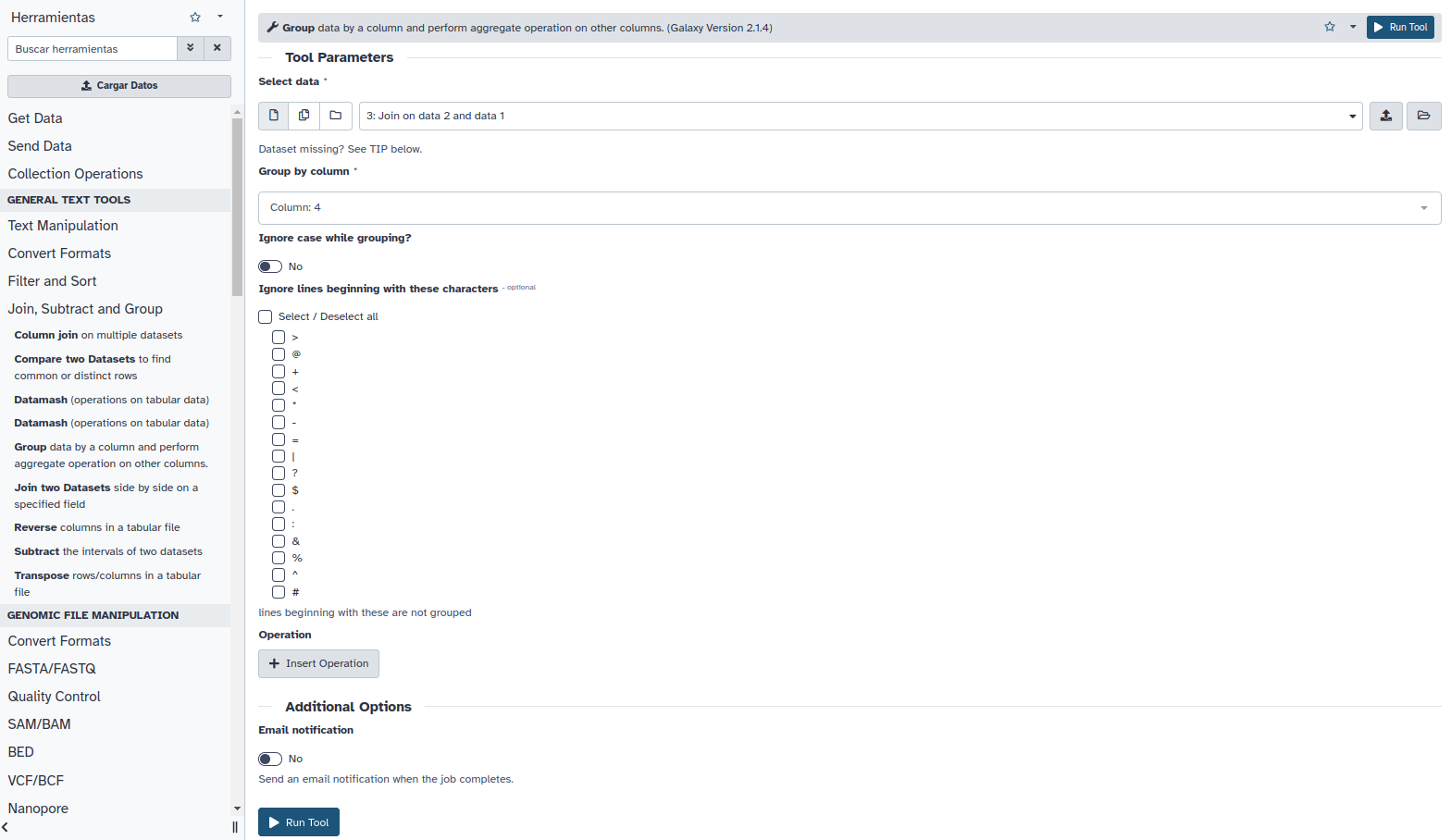
Seleccione la columna 4 escribiendo “c4″ en Group by column o seleccionándola del desplegable. Pinche luego en Insert Operation y asegúrese de elegir la operación Count en la columna 4:
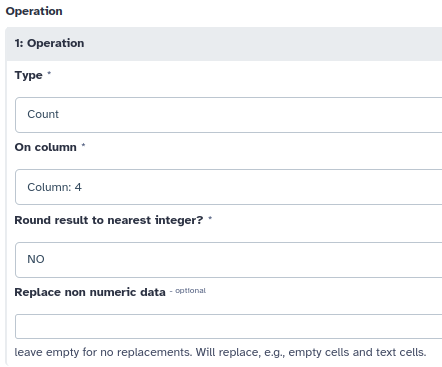
Pinchando en Execute se añadirá un nuevo elemento en su historial:
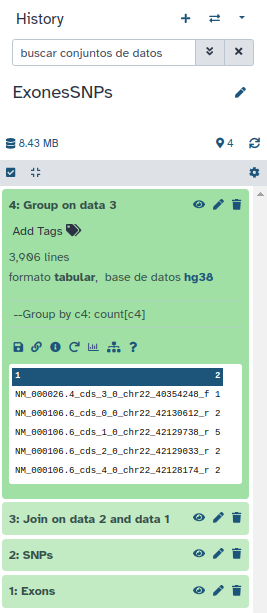
Este nuevo elemento contiene dos columnas. La primera es el nombre del exon, mientras que la segunda indica el número de veces que se repite (que equivale al número de SNPs que contiene cada exon).
Ordenando la lista por el número de repeticiones
Para determinar los exones con más SNPs, debemos editar esta lista ordenando por la segunda columna en orden descendente. “Filter and Sort -> Sort“:
Esto dará lugar al quinto item en su historia:
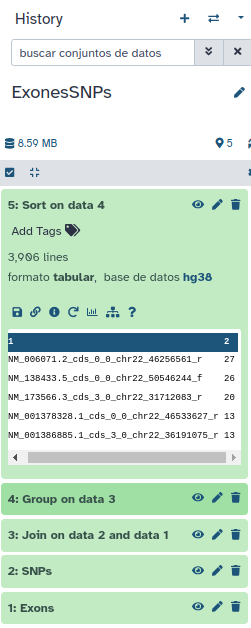
con lo que puede ver que el numero mayor de SNPs por exon es 27 (este número puede variar si esta usando una versión más reciente de la base de datos).
Selección de los cinco primeros
“Text Manipulation -> Select First“:
Pinchando en Execute se generará el sexto item en su historia, que contendrá sólo cinco líneas:

Recuperación de las coordenadas de los exones
Ahora sabemos que los cinco exones con más SNPs contienen entre 13 y 27 SNPs (de nuevo, recuerde que estos números pueden variar si esta usando una versión más reciente de la base de datos).
Para obtener más información acerca de estos exones, debemos recuperar su información posicional (sus coordenadas). Esta información se ha perdido en el proceso de agrupamiento, y ahora solo tenemos dos columnas.
Para volver a obtener las coordenadas, debemos emparejar los nombres de los exones en el último item (columna 1) con los nombres de los exones en el primer item (columna 4).
“Join, Subtract and Group -> Compare two Datasets” (preste atención a los valores seleccionados en cada campo del panel central):
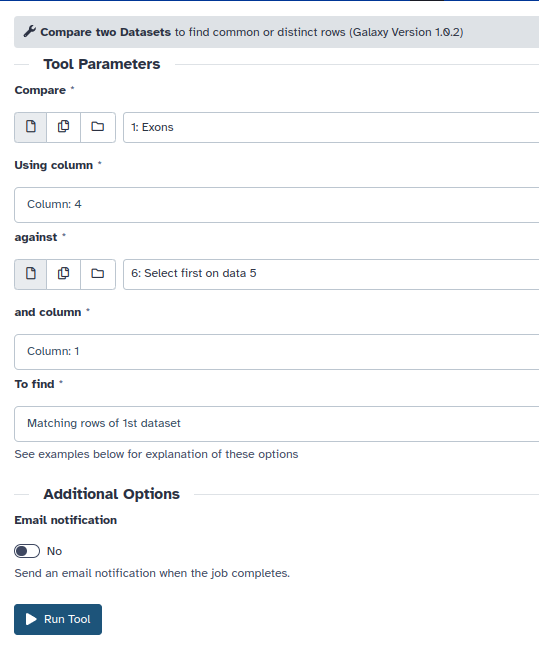
Lo que añade el item 7 a la historia:
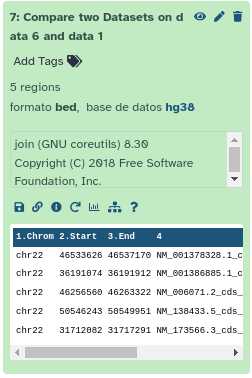
Visualización de los resultados
Con el botón ‘Ojo’, puede examinar los últimos datos obtenidos:
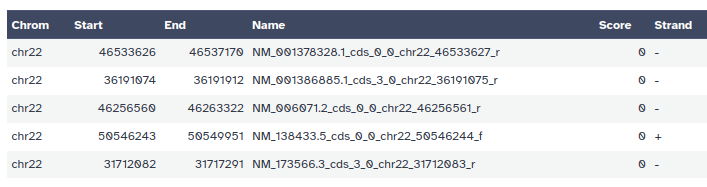
Representación de los datos en el navegador genómico de la UCSC
Puesto que ya tenemos sus coordenadas, la mejor manera de aprender más sobre estos exones es representarlos en su contexto mediante un navegador genómico. Para ello utilizaremos el buscador genómico de la UCSC:
![]()
Pulse en el icono del objeto Visualize (icono del gráfico de barras) y aparecerá la siguiente ventana:

Aquí seleccione display at UCSC. Obtendrá una imagen parecida a esta si hace zoom sobre los distintos exones (el track con sus datos aparecerá en la parte de arriba de la imagen “User Track”):
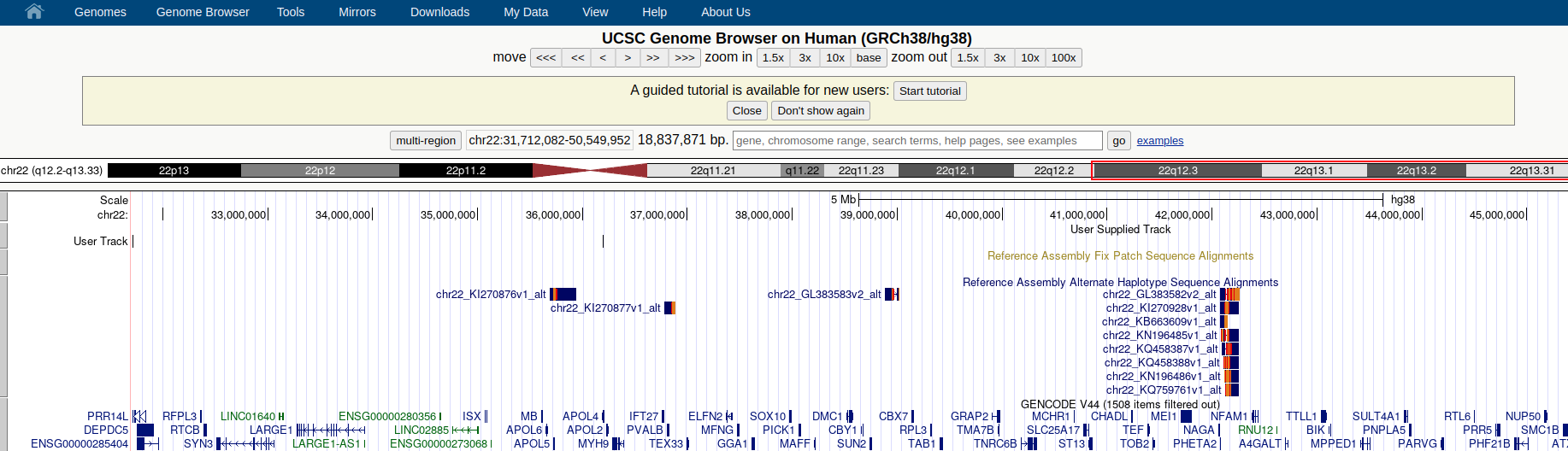
Y añadiendo las pistas de genes y SNPs podemos observar visualmente la localización del exón seleccionado junto con diferentes anotaciones.
